qt8gt0bxhw|20009F4EEE83|RyanMain|subtext_Content|Text|0xfbff514a00000000b700000001000900
There are many secure websites out there that provide useful information but do not have a public API to access it's data. A prime example of this is the LinkedIn website. You might love to gather some info from LinkedIn, but their promise to deliver a public API has yet to come to fruition. The problem is, the pages with all the good data are secure, requiring the user to log in before accessing these pages. Let's say we want to scrape this data from these pages programatically? We need to authenticate to access these pages. We can do that by reusing the authentication cookie from the site that we receive when we log in with a browser.
Note: I've mentioned LinkedIn as an example of a secure site to programatically access data from. It's actually a violation of LinkedIn's user agreement to scrape data from it's site. The techniques here apply to any form-based authenticated website, built on ASP.NET or anything else.
Before we move on with this, I wanted to state a few assumptions with the approach I'll be showing here:
- You already have browser-based access to the secure pages (meaning you have a user account).
- You're OK to use your own authentication cookie to access the secure pages without violating some site agreement. Doing this sort of thing on a site that prohibits it can get you banned from the site. Remember, you'll be using something that can link these requests back to your own user account.
When you visit a webpage that requires some sort of form-based authentication, usually there is an authentication token stored in a cookie. This certainly is the case with any ASP.NET site using Forms Authentication and is the case with LinkedIn as well as about any other similar site out there. Even if it isn't a persistent cookie, and is only active for the session, there still is a cookie. This cookie is passed back to the website in the request header each time a page is accessed. We can sniff out the data for that cookie using
Firebug (the awesomely-awesome Firefox addon), or using
Fiddler for IE.
Using Firebug, we can access the secure page and take a look at the cookie value in the header. For my example, I'll be using a sample ASP.NET site using forms authentication, but this all works the same for non-ASP.NET sites too.
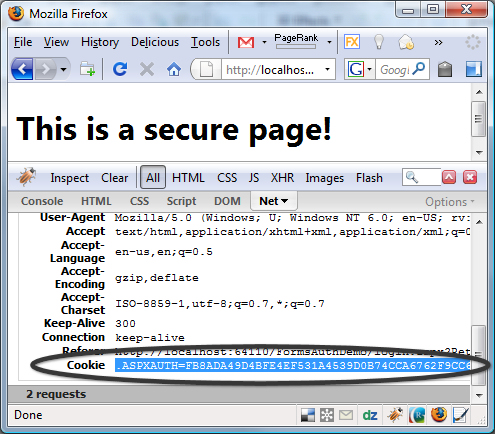
If you're using Fiddler, just access the page using IE and then you'll see the cookie data by going to the Headers section under the Session Inspector.
For an ASP.NET site using forms authentication, the authentication token name is indicated in the "name" attribute of the forms key in the authentication section of the web.config. By default that name is ".ASPXAUTH", but you won't know what that name is, or the site might not even be an ASP.NET site. That is OK. You can usually pick out the authentication token in the cookie data, or just use the entire cookie.
Now, using that cookie, we can use the following code to access the secure webpage:
using System.Net;
using System.IO;
//...
//grab cookie authentication token from Firebug/Fiddler and add in here
string cookiedata = ".ASPXAUTH=FB8ADA49D4BFE4EF531A4539D0B74CCA6762F9CC6F62C8E...";
HttpWebRequest request = HttpWebRequest.Create("http://somesite.com/securepage.aspx") as HttpWebRequest;
//set the user agent so it looks like IE to not raise suspicion
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)";
request.Method = "GET";
//set the cookie in the request header
request.Headers.Add("Cookie", cookiedata);
//get the response from the server
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream))
{
string pagedata = reader.ReadToEnd();
//now we can scrape the contents of the secure page as needed
//since the page contents is now stored in our pagedata string
}
}
response.Close();
One thing to point out here, since we're passing the entire contents of the cookie, I'm just adding that as a whole to the request header instead of adding each cookie element to the request.Cookie container.
If I wire that up in a form, we'll quickly see the secure page since the site will see the authentication token in the cookie sent in the page header and will not redirect us to the login page.
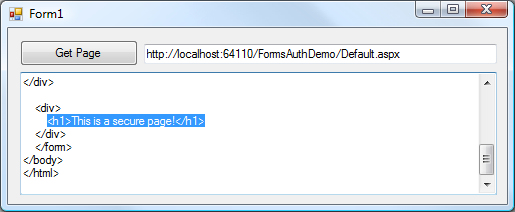
Not bad. We can now scrape any data we'd like from the secure page contents. Just to point out, we're not just limited to reading the data. We can also send form data back to the site as a POST on secure pages as well.